Human-level contact-rich manipulation relies on the distinct roles of two key modalities: vision provides spatially rich but temporally slow global context, while force sensing captures rapid, high-frequency local contact dynamics. Integrating these signals is challenging due to their fundamental frequency and informational disparities.
In this work, we propose ImplicitRDP, a unified end-to-end visual-force diffusion policy that integrates visual planning and reactive force control within a single network. We introduce Structural Slow-Fast Learning, a mechanism utilizing causal attention to simultaneously process asynchronous visual and force tokens, allowing the policy to perform closed-loop adjustments at the force frequency while maintaining the temporal coherence of action chunks.
Furthermore, to mitigate modality collapse where end-to-end models fail to adjust the weights across different modalities, we propose Virtual-target-based Representation Regularization. This auxiliary objective maps force feedback into the same space as the action, providing a stronger, physics-grounded learning signal than raw force prediction.
Extensive experiments on contact-rich tasks demonstrate that ImplicitRDP significantly outperforms both vision-only and hierarchical baselines, achieving superior reactivity and success rates with a streamlined training pipeline.
ImplicitRDP is an end-to-end policy that unifies low-frequency visual planning and high-frequency force control. Instead of a handed-designed hierarchy like RDP, we utilize Structural Slow-Fast Learning (SSL). We concatenate slow visual tokens and fast force tokens into a unified sequence. By employing a temporally causal structure (GRUs and causal attention mask), the policy can perform closed-loop adjustments at the force frequency while maintaining the temporal coherence of action chunks.
Fig. 1: Network Architecture. We enforce a temporally causal structure using a GRU for force signal encoding and a causal attention mask for action-force interaction. This design enables the model to effectively process asynchronous visual and force tokens simultaneously.
To enable high-frequency closed-loop control within an action chunk, we employ a consistent inference mechanism. Since standard diffusion sampling is stochastic, independent sampling at each step would lead to jittery, inconsistent actions. We address this by using a deterministic DDIM sampler with cached initial noise and slow visual tokens. At each high-frequency control step, we only update the fast force tokens and rerun the denoising process on the extended noisy action sequence. This ensures the generated trajectory remains smooth and consistent while reacting to new force feedback in real-time.

Algorithm 1: Consistent Inference in ImplicitRDP. We perform slow observation encoding and noise sampling only once at the beginning of a chunk. During the fast loop, we reuse the cached noise and slow context while updating fast force tokens to generate the latest reactive action.
To mitigate modality collapse where end-to-end models ignore force feedback, we introduce Virtual-target-based Representation Regularization (VRR). Rather than predicting raw future forces, we train the model to predict a "virtual target" derived from compliance control theory. This maps force feedback into the same space as the action and adaptively weights the loss based on force magnitude, forcing the model to internally align force feedback with motion planning.
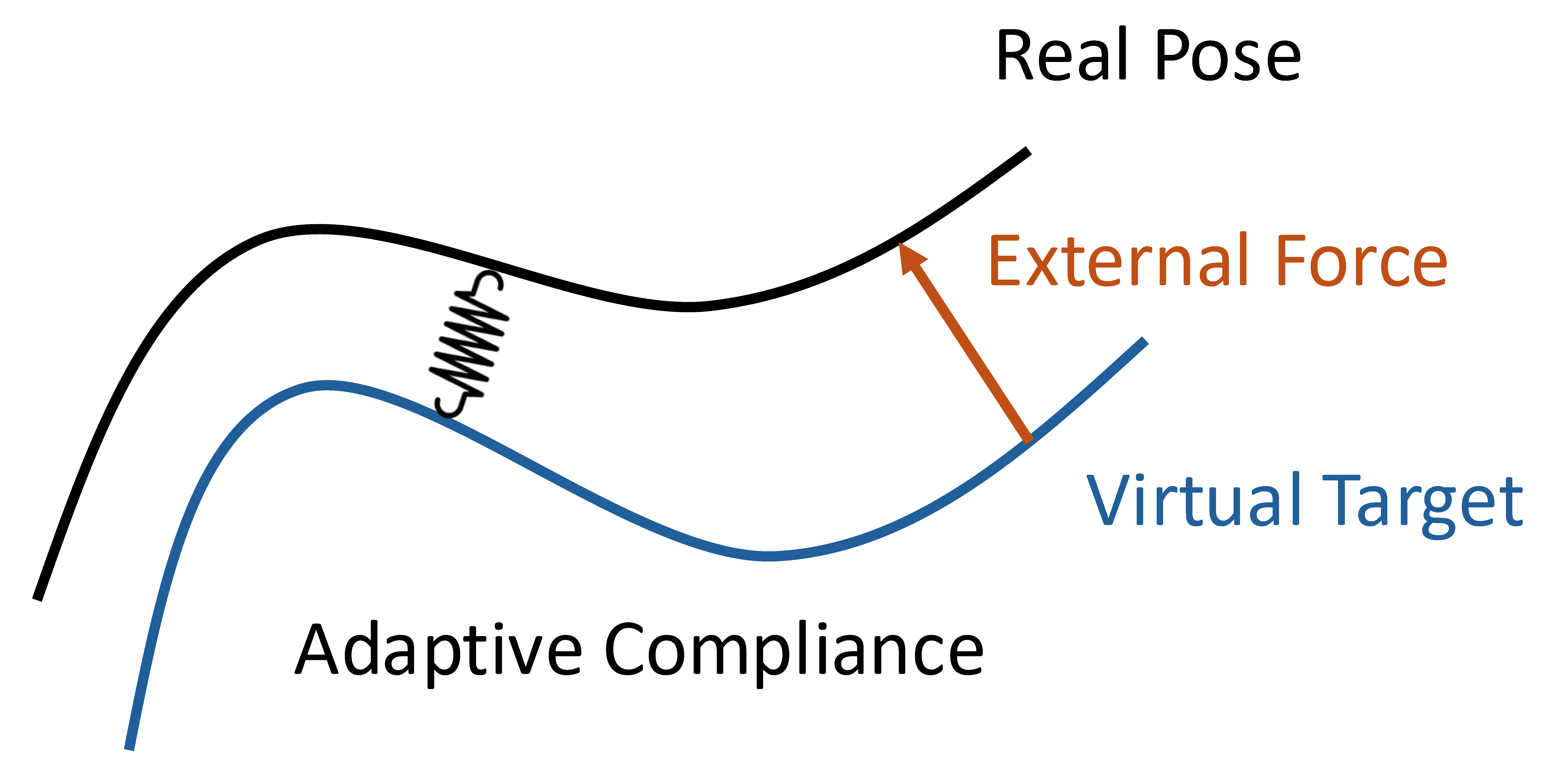
Fig. 2: Virtual Target. The virtual target represents the trajectory position that the robot intends to track under a specific stiffness. We apply adaptive stiffness to weight high-force contact events more heavily, encouraging the policy to attend to critical force feedback.
We compare ImplicitRDP against a vision-only method (DP) and a hierarchical baseline (RDP). Experiments on Box Flipping and Switch Toggling demonstrate that our end-to-end approach significantly outperforms baselines. While DP fails to regulate force and RDP struggles with contact precision, ImplicitRDP achieves the highest success rates by effectively integrating visual planning with reactive force control.
TABLE I: Success Rate Compared with Baseline Methods
| Method | Box Flipping | Switch Toggling |
|---|---|---|
| DP | 0/20 | 8/20 |
| RDP | 16/20 | 10/20 |
| ImplicitRDP (Ours) | 18/20 | 18/20 |
To validate the effectiveness of Structural Slow-Fast Learning (SSL), we compare the full model against open-loop variants. Removing SSL leads to a significant performance drop, especially in tasks requiring sustained force maintenance like Box Flipping. The results confirm that the closed-loop force control enabled by SSL is critical for contact-rich manipulation.
TABLE II: Comparison Between Open-Loop and Closed-Loop Control
| Method | Box Flipping | Switch Toggling |
|---|---|---|
| ImplicitRDP w.o. SSL & VRR | 6/20 | 5/20 |
| ImplicitRDP w.o. SSL | 4/20 | 15/20 |
| ImplicitRDP (Ours) | 18/20 | 18/20 |
We investigate the impact of Virtual-target-based Representation Regularization (VRR) compared to standard Force Prediction or no auxiliary task. VRR consistently yields the best performance while other auxiliary settings fail to effectively utilize high-frequency force signals which results in untimely loss of contact.
TABLE III: Comparison of Different Auxiliary Tasks
| Auxiliary Task | Box Flipping | Switch Toggling |
|---|---|---|
| None | 6/20 | 6/20 |
| Force Prediction | 8/20 | 10/20 |
| Virtual Target Prediction (Ours) | 18/20 | 18/20 |
As visualized in the attention map below, VRR encourages the network to adaptively attend to force tokens during contact phases, whereas models without VRR fail to utilize force information effectively.
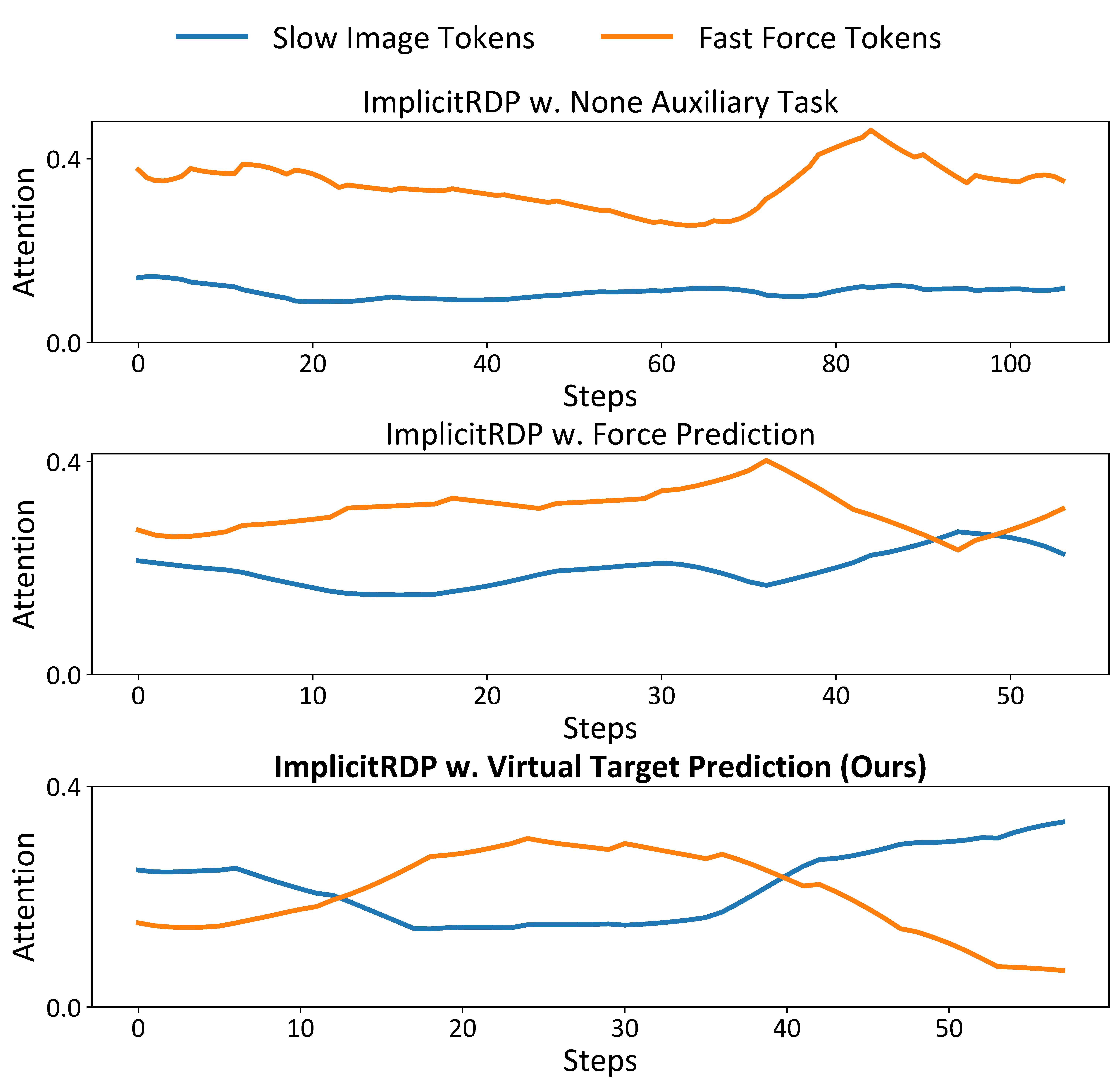
Fig 3. Attention Weight Visualization. We visualize the summed attention weights of visual tokens and force tokens from the first transformer layer in the switch toggling task. VRR enables adaptive attention to different modalities during different phases.
@article{chen2025implicitrdp,
title = {ImplicitRDP: An End-to-End Visual-Force Diffusion Policy with Structural Slow-Fast Learning},
author = {Chen, Wendi and Xue, Han and Wang, Yi and Zhou, Fangyuan and Lv, Jun and Jin, Yang and Tang, Shirun and Wen, Chuan and Lu, Cewu},
journal = {arXiv preprint arXiv:2512.10946},
year = {2025}
}
@inproceedings{xue2025reactive,
title = {Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation},
author = {Xue, Han and Ren, Jieji and Chen, Wendi and Zhang, Gu and Fang, Yuan and Gu, Guoying and Xu, Huazhe and Lu, Cewu},
booktitle = {Proceedings of Robotics: Science and Systems (RSS)},
year = {2025}
}